
seaborn은 matplotlib 처럼 그래프를 그리는 기능이다.
( matplotlip의 활용에 대해 알고 싶다면 아래 링크를 참고하자.)
matplotip으로도 대부분의 시각화는 가능하지만,
최근에는 다음과 같은 이유로 seaborn이 더 많이 쓰인다.
1. seaborn에서만 제공되는 통계 기반 plot
2. 특별하게 꾸미지 않아도 깔끔하게 구현되는 기본 color
3. 더 아름답게 그래프 구현이 가능한 palette 기능
4. pandas 데이터프레임과 높은 호환성
: hue 옵션으로 bar 구분이 가능하며, xtick, ytick, xlabel, ylabel, legend 등이 추가적인 코딩 작업없이 자동으로 세팅된다.
그럼 이제부터 seaborn 데이터 시각화를 위한 다양한 그래프와 차트들을 총정리해보자!
먼저 그래프 구현에 앞서 필요한 라이브러리를 import 해준다.
| 1 2 3 4 |
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns |
한글 폰트도 설치 해주자.
| 1 2 3 4 |
# 한글 폰트 적용 plt.rc('font', family='NanumBarunGothic') # 캔버스 사이즈 적용 plt.rcParams["figure.figsize"] = (12, 9) |
seaborn 실습을 위해 샘플 데이터로 Titanic data-set을 로드한다.(seaborn.load_dataset : seaborn 연습이 가능한 샘플 데이터를 제공해준다)
| 1 2 |
titanic = sns.load_dataset('titanic') titanic |

survived: 생존여부
pclass: 좌석등급
sex: 성별
age: 나이
sibsp: 형제자매 + 배우자 숫자
parch: 부모자식 숫자
fare: 요금
embarked: 탑승 항구
class: 좌석등급 (영문)
who: 사람 구분
deck: 데크
embark_town: 탑승 항구 (영문)
alive: 생존여부 (영문)
alone: 혼자인지 여부
또 다른 샘플 데이터를 로드한다.
| 1 2 |
tips = sns.load_dataset('tips') tips |

total_bill: 총 합계 요금표
tip: 팁
sex: 성별
smoker: 흡연자 여부
day: 요일
time: 식사 시간
size: 식사 인원
이제 본격적으로 seaborn을 활용하여 다양한 그래프와 차트를 구현해보자!
1. countplot
– 항목별 갯수를 세어주는 countplot 입니다.
– 알아서 해당 column을 구성하고 있는 value들을 구분하여 보여준다.
| 1 2 |
# 차트 배경 설정 sns.set_style('whitegrid') |
| 1 2 3 |
# 차트 세로로 그리기 sns.countplot(x="class", hue="who", data=titanic) plt.show() |

| 1 2 3 |
# 차트 가로로 그리기 : x를 y로 변경하면 세로에서 가로 차트로 변경 가능 sns.countplot(y="class", hue="who", data=titanic) plt.show() |

| 1 2 3 |
# palette 설정 sns.countplot(x="class", hue="who", palette='Accent', data=titanic) plt.show() |

어떤 palette를 설정할지 코드를 모르는 경우가 많은데 이럴 때는 아래처럼 코드 오류를 내면 사용 가능한 palette 코드를 확인 가능하다.

2. distplot
– matplotlib의 hist 그래프와 kdeplot을 통합한 그래프 이며, 분포와 밀도를 확인할 수 있다.
| 1 2 3 |
# distplot을 구현하기 위한 샘플 데이터를 생성 x = np.random.randn(100) x |

| 1 2 3 |
# 기본 distplot sns.distplot(x) plt.show() |

기본 distplot
| 1 2 3 4 5 |
# rugplot # rug는 rugplot이라고도 불리우며, 데이터 위치를 x축 위에 **작은 선분(rug)으로 나타내어 # 데이터들의 위치 및 분포**를 보여준다. sns.distplot(x, rug=True, hist=False, kde=True) plt.show() |

rugplot
| 1 2 3 4 |
# kde(kernel density)plot # kde는 histogram보다 부드러운 형태의 분포 곡선을 보여주는 방법 sns.distplot(x, rug=False, hist=False, kde=True) plt.show() |

kdeplot
| 1 2 |
# 가로로 표현하기 sns.distplot(x, vertical=True) |

vertical = True로 변경하면 가로로 표현 가능!
| 1 2 3 |
# 컬러 변경하기 sns.distplot(x, color="y") plt.show() |

color 파라미터 활용하여 색 변경도 가능!
3. heatmap
– 색상으로 표현할 수 있는 다양한 정보를 일정한 이미지위에 열분포 형태의 비쥬얼한 그래픽으로 출력 가능하다.
| 1 2 3 4 |
# 기본 heatmap heatmap_data = np.random.rand(10, 12) sns.heatmap(heatmap_data, annot=True) #annot=True로 해야 수치 표현도 가능 plt.show() |

0에 가까울 수록 색이 진해지고, 1에 가까울 수록 색이 연해진다.
pivot table을 활용해서 heatmap을 그릴 수 있다.
위에서 블러왔던 tips 데이터를 pivot table 형태로 가공 후 heatmap으로 표현해보자.

| 1 2 |
pivot = tips.pivot_table(index='day', columns='size', values='tip') pivot |

| 1 2 |
sns.heatmap(pivot, cmap='Blues', annot=True) #cmap으로 전체적인 컬러 조정 가능 plt.show() |

값이 클수록 진하게 표시되어 어떤 요일에 평균적인 식사 인원수가 많은지 한눈에 알 수 있다.
상관관계를 표시할 때도 heatmap을 유용하게 사용할 수 있다.
| 1 2 |
# corr() 함수는 데이터의 상관관계를 보여준다. titanic.corr() |

| 1 2 |
sns.heatmap(titanic.corr(), annot=True, cmap="YlGnBu") plt.show() |

상관관계가 1에 가까울 수록 진하게 표시된다.
상관계수는 일반적으로
값이 -1.0 ~ -0.7 이면, 강한 음적 상관관계
값이 -0.7 ~ -0.3 이면, 뚜렷한 음적 상관관계
값이 -0.3 ~ -0.1 이면, 약한 음적 상관관계
값이 -0.1 ~ +0.1 이면, 없다고 할 수 있는 상관관계
값이 +0.1 ~ +0.3 이면, 약한 양적 상관관계
값이 +0.3 ~ +0.7 이면, 뚜렷한 양적 상관관계
값이 +0.7 ~ +1.0 이면, 강한 양적 상관관계
로 해석된다.
4. pairplot
– pairplot은 그리도(grid) 형태로 각 집합의 조합에 대해 히스토그램과 분포도를 그린다.
– 또한, 숫자형 column에 대해서만 그려준다.
tips 데이터를 바탕으로 Pairplot을 구현해보자.

다양한 조합의 히스토그램과 분포도를 한눈에 확인 할 수 있다.
| 1 2 3 |
# hue 옵션으로 구분해서 볼수도 있다. sns.pairplot(tips, hue='size') plt.show() |

5. violinplot
– 바이올린처럼 생긴 차트
– column에 대한 데이터의 비교 분포도를 확인할 수 있다.
– 곡선진 부분 (뚱뚱한 부분)은 데이터의 분포를 나타낸다.
– 양쪽 끝 뾰족한 부분은 데이터의 최소값과 최대값을 나타낸다.
| 1 2 3 |
# 기본 violinplot 그리기 sns.violinplot(x=tips["total_bill"]) plt.show() |

| 1 2 3 |
# x, y축을 지정해줌으로썬 바이올린을 분할하여 비교 분포를 볼 수 있다. sns.violinplot(x="day", y="total_bill", data=tips) plt.show() |

| 1 2 3 |
# violinplot의 하이라이트로 split 옵션으로 바이올린을 합쳐서 볼 수 있다. sns.violinplot(x="day", y="total_bill", hue="smoker", data=tips, palette="muted", split=True) plt.show() |

6. lmplot
– lmplot은 column 간의 선형관계를 확인하기에 용이한 차트
– 또한, outlier도 같이 짐작해 볼 수 있다.
| 1 2 |
sns.lmplot(x="total_bill", y="tip", height=8, data=tips) plt.show() |

hue 옵션으로 다중 선형관계 그릴 수 있다.
| 1 2 |
sns.lmplot(x="total_bill", y="tip", hue="smoker", height=8, data=tips) plt.show() |

아래의 그래프를 통하여 비흡연자가, 흡연자 대비 좀 더 가파른 선형관계를 가지는 것을 볼 수 있다.
또한 col 옵션을 추가하여 그래프를 별도로 그려볼 수 있다.
| 1 2 3 |
# col_wrap으로 한 줄에 표기할 column의 갯수를 명시할 수 있다. sns.lmplot(x='total_bill', y='tip', hue='smoker', col='day', col_wrap=2, height=6, data=tips) plt.show() |

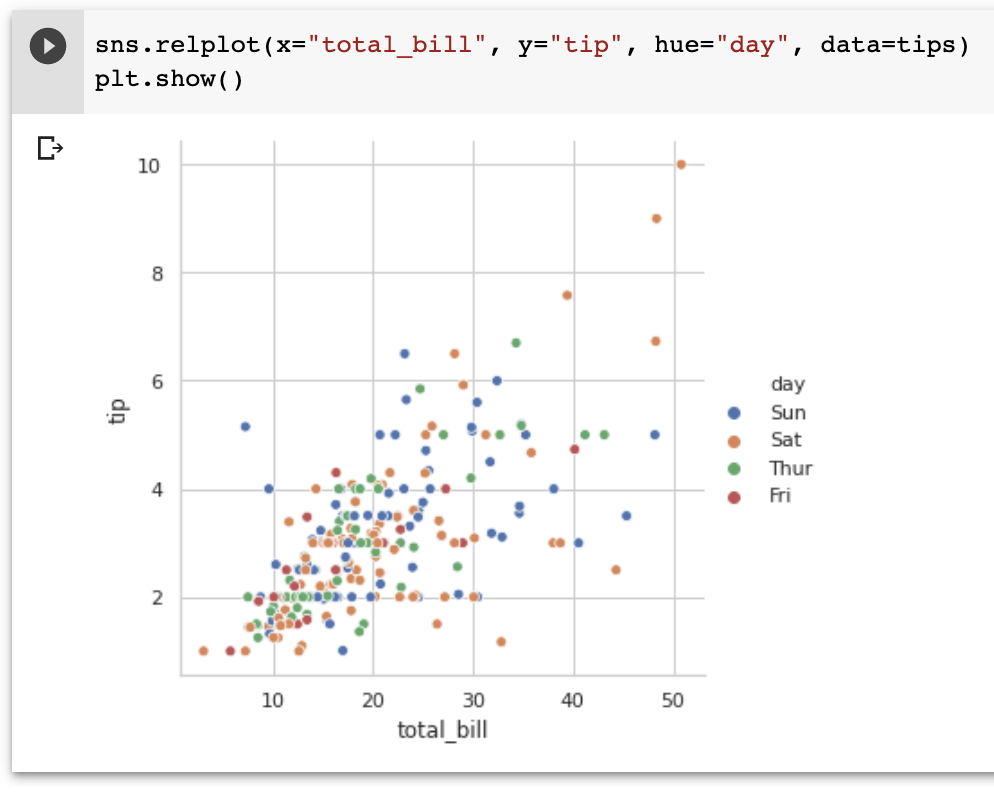
7. replot
– 두 column간 상관관계를 보지만 lmplot처럼 선형관계를 따로 그려주지는 않는다.
| 1 2 |
sns.relplot(x="total_bill", y="tip", hue="day", data=tips) plt.show() |
| 1 2 3 |
# row와 column에 표기할 데이터 column 선택하여 표현 가능 sns.relplot(x="total_bill", y="tip", hue="day", row="sex", col="time", data=tips) plt.show() |

8. jointplot
– scatter(산점도)와 histogram(분포)을 동시에 그려주며 숫자형 데이터만 표현 가능
| 1 2 |
sns.jointplot(x="total_bill", y="tip", height=8, data=tips) plt.show() |

선형관계를 표현하는 regression 라인 그리기도 가능하다.
| 1 2 3 |
# 옵션에 kind='reg'을 추가 sns.jointplot("total_bill", "tip", height=8, data=tips, kind="reg") plt.show() |

'데이터 시각화' 카테고리의 다른 글
| 데이터 시각화 형태 고르기 (0) | 2021.07.26 |
|---|---|
| Seaborn(SNS)를 사용한 파이썬 데이터 시각화 기초 matplotlib (0) | 2021.07.14 |


댓글