로지스틱 회귀분석은 Logistic regression analysis로 표기하면 로짓분석(Logit analysis)라고도 한다.

Cox(1970)가 처음 제시한 개념으로 두개의 값만을 가지는 종속변수와 독립변수들 간의 인과관계를 로지스틱 함수를 이용하여 추정하는 통계기법이다.
로지스틱 회귀분석은 어떤 사건(event)이 발생할지에 대한 직접 예측이 아니라 그 사건이 발생할 확률을 예측하는 것이다.
로지스틱 회귀분석이 사용되는 예를 보면,
금융권에서는 고객의 신용도 평가를 통해 이 고객의 신용도가 우량이 될 것인지, 신용불량자가 될 것인지 미리 예측해 볼 수 있다. 또한 통신사의 경우 2년 약정 종료 후 번호이동으로 타 통신사로 갈 것인지, 기기변경으로 남을 것인지 판단할 수 있다.
제과점에서는 전날 저녁에 다음날 팔게 될 빵의 수량을 예측해서 본사에 주문하거나 직접 만들게 되는데 이때 재고를 남기지 않고 모두 판매할 수 있을지 폐기하게 될지 등을 예측하는데 활용해 볼 수 있을 것이다.
무엇보다 의학 분야에서는 다양한 원인을 파악하여 질병에 대한 예측을 하는데 더욱 효과적으로 활용해 볼 수 있을 것이다.

로지스틱 회귀모형은 반응변수가 범주형 자료(이항/다항)이며, 일반화 선형모형(generalized linear model)의 특수한 경우로 S형 곡선을 그리는 함수 모형이다.
특히, 로지스틱 회귀분석을 위한 종속변수는 이분형으로 0 또는 1의 값을 가지고, 독립변수는 범주형 또는 연속형 모두 가능하다.
로지스틱 회귀모형은 여러 설명 변수들로부터 두 범주만을 가지는 반응변수를 예측하는데 사용하며, 분석결과 종속변수 값, 즉 확률이 0.5보다 크면 그 사건이 일어나며, 0.5보다 작으면 그 사건이 일어나지 않는 것으로 예측한다.

단순회귀분석과 다중회귀분석으로 대표되는 선형 회귀분석은 기본적으로 종속변수와 독립변수 모두 연속형 변수이어야 했으며, 예외적으로 독립변수에 한하여 명목척도를 더미변수로 변환하여 분석할 수가 있었다.
이분형 로지스틱 회귀분석은 독립변수는 선형회귀분석과 동일하지만 종속변수는 이분형으로 측정된 명목변수로 분석을 하는게 다른 부분이다.
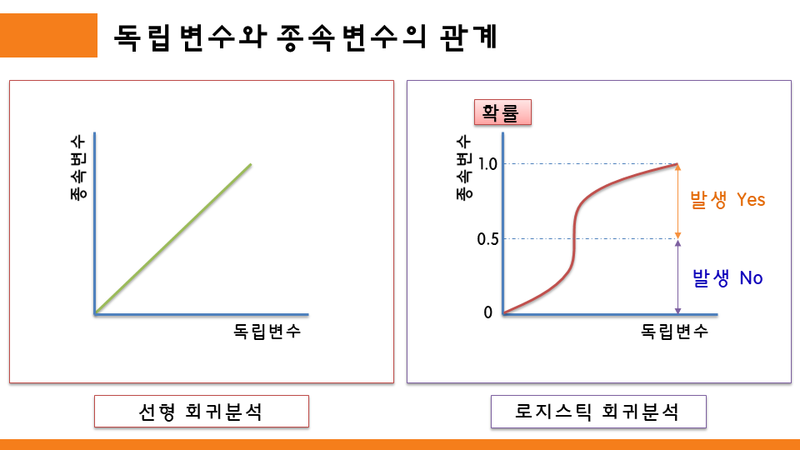
선형 회귀분석이 말 그대로 독립변수와 종속변수 사이의 선형적 관계를 그래프로 나타낸 것이라면, 로지스틱 회귀분석은 선형이 아닌 "S" 곡선의 특성을 나타낸다.
로지스틱 회귀분석의 곡선에서 종속변수의 확률이 0.5보다 크면 어떤 사건이 일어난다고 보고, 0.5보다 작으면 어떤 사건이 일어나지 않을 것이라고 확률적으로 예측해볼 수 있다.

오즈비(Odds Ratio) 또는 승산비 또는 줄여서 OR이라는 것은 확률과 관련된 의미로서, 미국의 라스베가스에서는 포커에서 내가 이길 확률을 계산할 때 주로 거론되는 용어라고 한다.
오즈비는 P가 주어졌을 때, 사건이 발생활 확률이 발생하지 않을 확률에 비해 몇배 더 높은가의 의미를 가지고 있다.
이것을 공식으로 나타내면,
Odds=(사건이 발생함)/(사건 발생안함)으로 나타낼 수 있고, 이것은
Odds= P / (1-P) 로 표기할 수 있다. 결국 이것은

이와 같이 지수함수로 표현할 수 있다.
이러한 지수함수는 다중회귀분석에서 회귀식의 표현과 거의 유사한 형태를 가지고 있다.
오즈비의 공식을 통해 예를들어보면, 종속변수의 범주가 ‘1’이 성공이고 ‘0’은 실패인 이분형을 가정할 때, P가 0.8이라면, 오즈비는
(0.8/(1-0.8))=4가 되고 이것은 성공이 될 확률이 실패가 될 확률보다 4배 높다는 의미를 가진다.
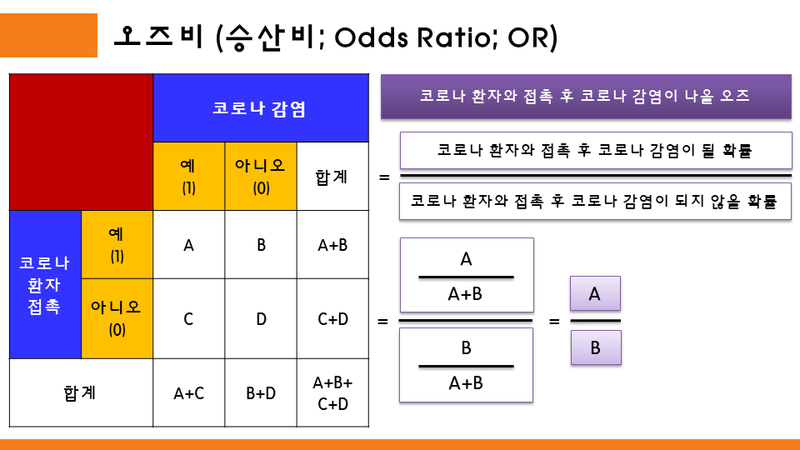
오즈비를 요즘 전세계적으로 창궐하고 있는 코로나19 감염에 비유하여 예를들어보고자 한다.
A: 코로나 환자와 접촉 후, 코로나에 감염 됨
B: 코로나 환자와 접촉 후, 코로나에 감염되지 않음
C: 코로나 환자와 접촉하지 않았지만, 코로나에 감염 됨
D: 코로나 환자와 적촉하지 않았고, 코로나에 감염되지 않음
이와 같을 경우,
코로나 환자와 접촉 후 코로나 감염이 나올 오즈
=(코로나 환자와 접촉 후 코로나 감염이 될 확률) / (코로나 환자와 접촉 후 코로나 감염이 되지 않을 확률)
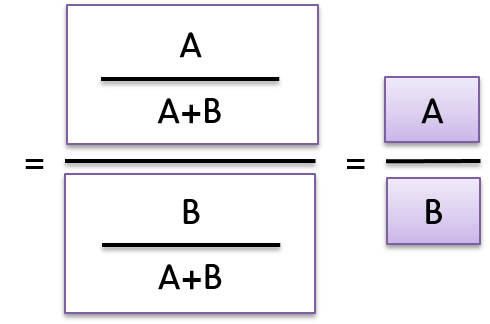
과 같이 공식으로 나타낼 수 있다. 반면,
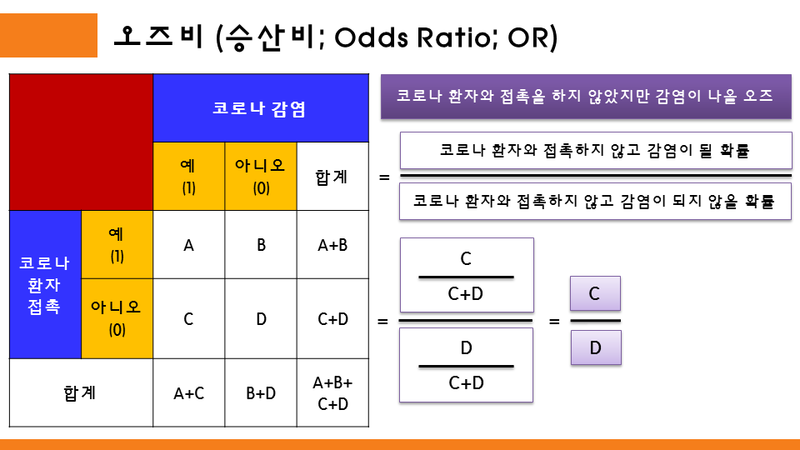
코로나 환자와 접촉을 하지 않았지만 감염이 나올 오즈
= (코로나 환자와 접촉하지 않고 감염이 될 확률) / (코로나 환자와 접촉하지 않고 감염이 되지 않을 확률)

과 같이 나타낼 수 있다. 위의 두 공식을 종합해서 오즈비를 나타내면,

오즈비(OR)
= (코로나 환자와 접촉 후 코로나 감염이 될 확률) / (코로나 환자와 접촉하지 않고 코로나 감염이 될 확률)

으로 종합해 볼 수 있다.
결국, 오즈비에 대한 공식은

으로 귀결된다.

자연지수 e를 ln으로 치환하면,

다중회귀분석의 회귀식과 동일하게 나오는것을 볼 수 있다.

오즈비의 해석 방법은 확률 1을 기준으로 한다.
OR = 1 ▶ 코로나 환자와 접촉했다고 해서 코로나 감염에 유의미한 영향을 준다고 볼 수 없다.
OR > 1 ▶ 코로나 환자와 접촉한 경우 접촉하지 않은 경우보다 오즈비 만큼 더 높게 나타날 것이다.
OR < 1 ▶ 코로나 환자와 접촉한 경우 접촉하지 않은 경우보다 오즈비 만큼 더 낮게 나타날 것이다.
참고적으로, 논문에 오즈비를 표기할 때는 95% 신뢰구간을 같이 표기하는게 좋다.
일반적으로 95% 신뢰구간에 오즈비 1을 포함하면, 유의미한 영향이 없다고 보고, 1을 포함하면, 유의미한 영향이 있다고 해석한다.
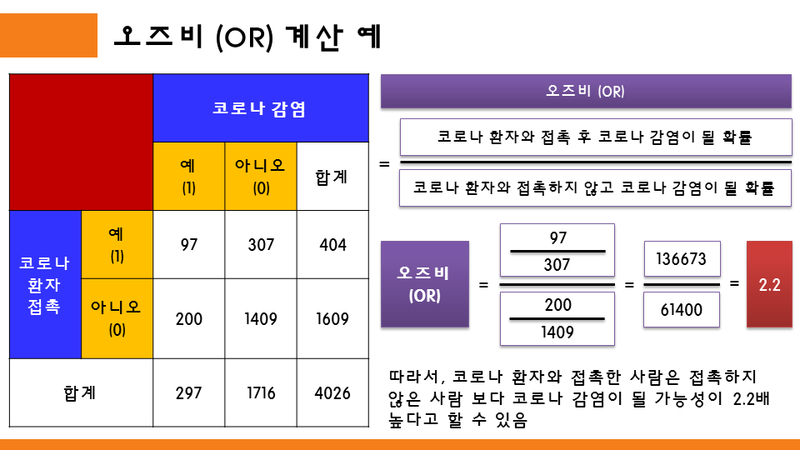
그렇다면, 위의 공식들을 사용하여, 실제 계산을 해보도록 하자.
A: 97명 - 코로나 환자와 접촉 후, 코로나에 감염 됨
B: 307명 - 코로나 환자와 접촉 후, 코로나에 감염되지 않음
C: 200명 - 코로나 환자와 접촉하지 않았지만, 코로나에 감염 됨
D: 1409명 - 코로나 환자와 적촉하지 않았고, 코로나에 감염되지 않음
일때,
OR=136673 / 61400 = 2.2 로 계산된다.
따라서, 코로나 환자와 접촉한 사람은 접촉하지 않은 사람 보다 코로나 감염이 될 가능성이 2.2배 높다고 할 수 있다.
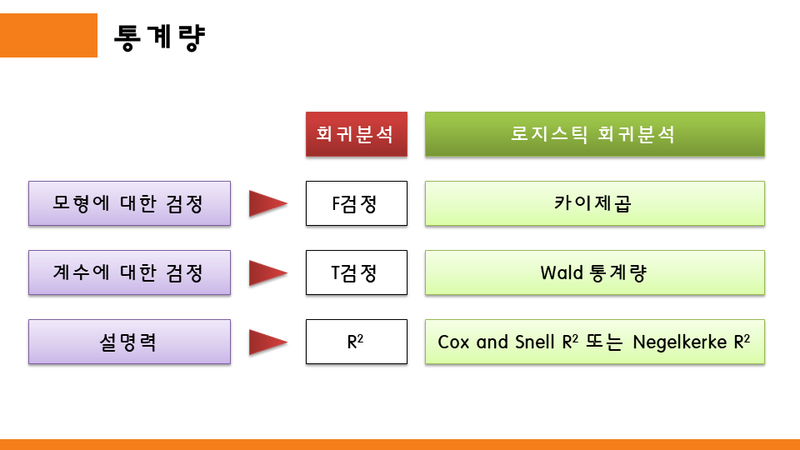
추론 통계 분석을 논문에 삽입할 경우 기본적으로 통계량과 유의확률(P값)을 같이 표기한다.
선형회귀분석에서 모형에 대한 검정을 위해 분산분석표의 F검정을 활용하였다.
계수에 대한 검정으로는 T검정을 사용하였으며, 모형에 대한 설명력은 R제곱과 수정된 R제곱으로 판단하였다.
로지스틱 회귀분석에서는
모형에 대한 검정으로 카이제곱을 활용한다.
계수에 대한 검정으로는 Wald 통계량을 활용하고, 논문에는 (Wald=000000, P<0.05)와 같이 표기한다.
모형에 대한 설명력으로는 Cox and Snell R제곱과 Negelkerke R제곱 두가지를 사용하는 보통 Negelkerke R제곱이 크게 나오기 때문에 Negelkerke R제곱을 주로 활용한다.
그러나 선형회귀분석의 R제곱 계수만큼 중요도가 높지는 않다.
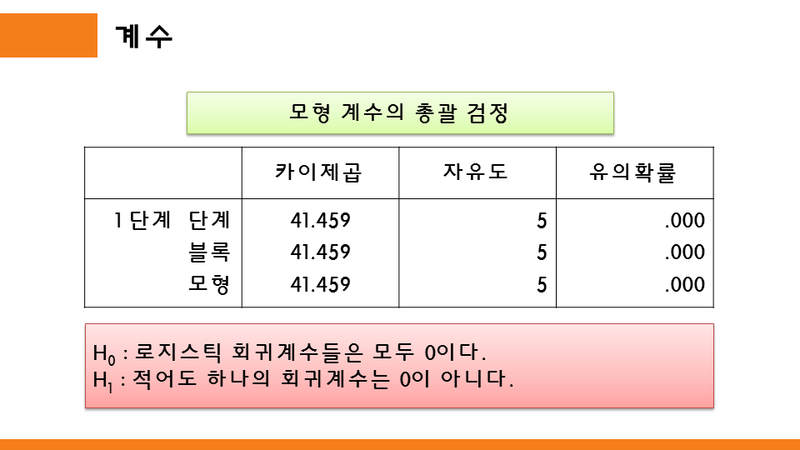
위에서 언급한 모형에 대한 검정으로 로지스틱 회귀분석 결과의 "모형 계수의 총괄 검정" 표에 카이제곱 값이 나타나 있다.
단계 : 가장 처음 투입된 독립변수의 계수에 대한 회귀모형의 유용성을 나타낸다.
블록 : 마지막으로 투입된 독립변수의 계수에 대한 회귀모형의 유용성을 나타낸다.
모형 : 독립변수 전체 계수에 대한 회귀모형의 유용성을 나타낸다.
동시입력 방식으로 모든 독립변수를 한번에 투입하였다면, 세가지 카이제곱 모두 같은 값이 나올 것이다.
여기에서
귀무가설(H0) : 로지스틱 회귀계수들은 모두 0이다.
대립가설(H1) : 적어도 하나의 회귀계수는 0이 아니다.
따라서, 로지스틱 회귀분석 사용하기 위해서는 귀무가설을 기각하고 대립가설을 채택해야 하므로 유의확률 P값은 유의수준(a=0.05) 보다 작게 나타나야 한다.
위의 표를 토대로 보면,
X2=41.459, P<0.001 으로 나타났으므로, 로지스틱 회귀계수들은 모두 0이다라는 귀무가설을 기각하고 대립가설을 채택할 수 있는 것으로 나타났다.
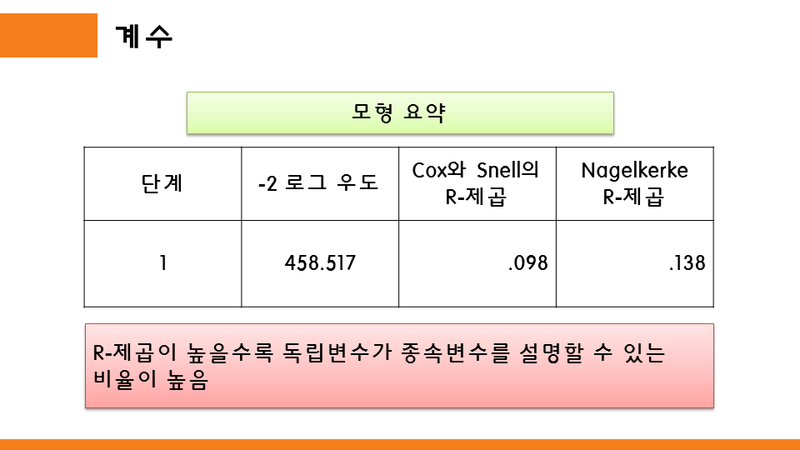
모형의 설명력은 로지스틱 회귀분석 결과의 "모형 요약" 표를 참고한다.
모형요약 표에는 모형 설명력을 위해 -2 로그우도, Cox와 Snee의 R-제곱, Nagelkerke R-제곱의 3가지를 제공한다.
-2 로그 우도(Likelihood; LL)는 이 값이 낮을수록 가장 완벽한 모형에 적합하다고 볼 수 있다.
Cox와 Snell의 R-제곱과 Nagelkerke R-제곱은 높을수록 가장 완벽한 모형에 적합하다고 볼 수 있다.
보통 Nagelkerke R-제곱 값이 높게 나타나기 때문에 Nagelkerke R-제곱 값을 주로 활용한다.
하지만 다중회귀분석에서 사용되는 결정계수 R 제곱만큼 중요도가 높지는 않다.

로지스틱 회귀분석 모형의 적합도는 Hosmerㅇ와 Lemeshow 검정 표를 활용한다.
Hosmer-Lemeshow 검정은 적합도 검정법의 하나로서, 추정된 로지스틱 모형이 적합하면 근사적으로 카이제곱 분포를 따르게 된다.
귀무가설(H0) : 추정된 모형이 잘 적합하다.
대립가설(H1) : 추정된 모형이 잘 적합하지 않다.
따라서, 모형이 적합하려면 대립가설을 기각하고 귀무가설을 채택해야 한다.
참고적으로 귀무가설을 반드시 채택해야 하는 분석 방법은
1. 정규성 검정, 2. 등분산성 검정, 3. 적합도 검정으로 요약해볼 수 있으며, 이는
유의확률(P) 값이 유의수준(a) 보다 커야 하는 것을 의미한다.
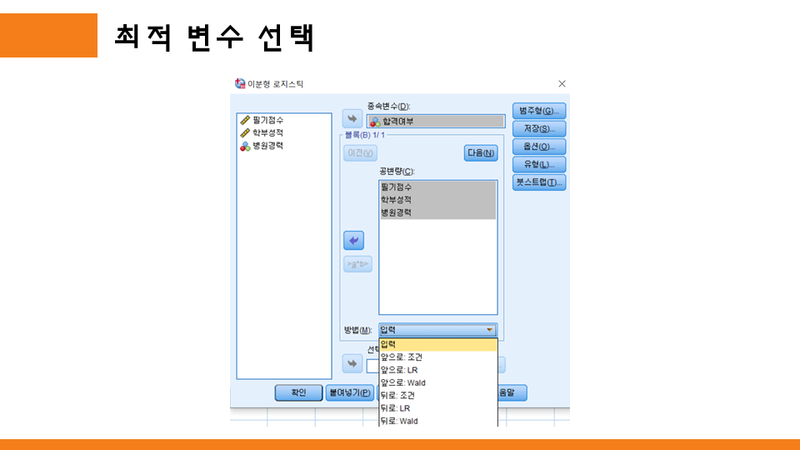
최적의 변수를 선택하기 위한 방법으로 다중회귀분석에도 동시입력과 단계선택 방법 외에 전진, 제거, 후진 등의 방법을 제공하는 것과 같이 로지스틱 회귀분석에도 7가지의 방법들을 제공하고 있다.
참고적으로 "앞으로"는 가장 유의하다고 판단되는 계수부터 순차적으로 삽입하는 방법이고,
"뒤로"는 가장 유의하지 않다고 판단되는 계수부터 순차적으로 삽입하는 방법이다.


1. 입력
▶ 모든 변수를 모형에 삽입한다.
2. 앞으로: 조건
▶ 스코어 통계량의 유의수준을 기준으로 변수의 진입 검정을 수행하고, 조건적 모수 추정값에 따라 우도비 통계량의 확률을 기초로 변수의 제거 검정을 수행하는 단계 선택법이다.
3. 앞으로: LR
▶ 스코어 통계량의 유의수준을 기준으로 변수의 진입 검정을 수행하고, 최대 편우도 추정값에 따라 우도비 통계량의 확률을 기초로 변수의 제거 검정을 수행하는 단계 선택법이다.
4. 앞으로: Wald
▶ 스코어 통계량의 유의수준을 기준으로 변수의 진입 검정을 수행하고, Wald 통계량의 확률을 기초로 변수의 제거 검정을 수행하는 단계 선택법이다.
5. 뒤로: 조건
▶ 조건적 모수 추정값에 따라 우도비 통계량의 확률을 기초로 변수의 제거 검정을 수행하는 후진제거 선택법이다.
6. 뒤로: LR
▶ 최대 편우도 추정값에 따라 우도비 통계량의 확률을 기초로 변수의 제거 검정을 수행하는 후진제거 선택법이다.
7. 뒤로: Wald
▶ Wald 통계량의 확률을 기초로 변수의 제거 검정을 수행하는 후진제거 선택법이다.
이상의 방법들은 뭐가 정확하다라고 정해진것은 없다.
연구자가 직접 옵션들을 선택해서 분석한 후 연구자에게 유리한 것으로 활용할수도 있고, 선행연구에서 선택한 방법을 그대로 따라할 수도 있을 것이다.
일반적으로는 1. 입력 방식과 3. 앞으로:LR 방식을 많이 활용하는 듯 하다.

범주형 변수 정의 대화상자는 범주형 변수를 자동으로 더미변수(Dummy Variable)로 변경해주는 역할을 한다. 더미변수를 이용한 다중회귀분석에서는 직접 더미변수를 생성하여 분석에 적용해야 했지만 로지스틱 회귀분석에서는 자동으로 생성해준다.
SPSS 26.0을 기준으로 7가지 옵션을 제공하는데 그 의미는 다음과 같다.

표시자 : 대비는 소속 범주가 있는지 여부를 나타냄, 기준범주는 대조행렬에서 ‘0’ 행으로 표현된다.
단순 : 범주형 공변량의 각 범주는 기준 범주와 비교된다.
차분 : 처음 범주를 제외한 점주형 공변량의 각 범주는 이전 범주의 평균 효과와 비교됨 이것을 역 Helmert 대비라고 한다.
Helmert : 마지막 범주를 제외한 범주형 공변량의 각 범주는 후속 범주들의 평균 효과와 비교된다.
반복 : 처음 범주를 제외한 범주형 공변량의 각 범주는 선행하는 범주와 비교된다.
다항 : 직교 다항대비. 범주는 동일한 간격으로 떨어져 있어야 함 다항대비는 숫자형 변수에 대해서만 사용할 수 있다.
편차 : 기준 범주를 제외한 범주형 공변량의 각 범주는 전체 효과와 비교된다.
이상의 7가지에 대하여 아직 정확하게 이해하지를 못했다.
일단은 기본적으로 표시자를 주로 사용한다고 하니, 표시자로 놓고 사용하면서 차근 차근 알아나가야겠다.
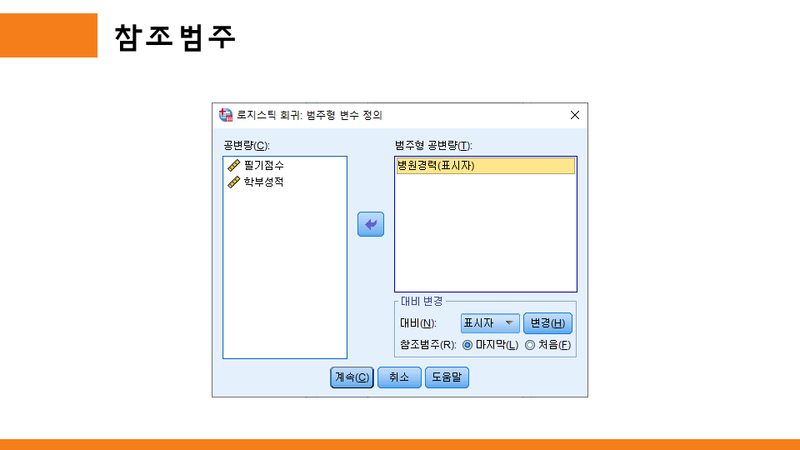
그리고, 참조범주(R):에 보면 "마지막"과 "처음"이라는 두가지 옵션이 있다.
이것은 더미변수를 만들때를 생각해보면 이해하기가 쉬울 것이다.

성별이라는 범주형 변수가 있을 때, 일반적 코딩은 남성=1, 여성=1로 코딩하지만 더미변수로 코딩할 때는 참조하고자 하는 변수 설정, 다시 말해서 레퍼런스 변수를 무엇으로 설정하느냐에 따라 해석이 달라진다.
위의 예제에서
참조변수를 마지막으로 할 경우
여성은 남성보다 OR 배 만큼 높거나 낮다로 해석할 수 있으며,
참조변수를 처음으로 할 경우
남성은 여성보다 OR 배 만큼 높거나 낮다로 해석할 수 있다.

범주가 3개 이상일 때는 위와 같이 코딩할 수 있다.
위의 예제에서
참조변수를 마지막으로 할 경우
종합병은 의원보다 OR 배 만큼 높거나 낮다,
병원은 의원보다 OR 배 만큼 높거나 낮다로 해석할 수 있으며,
참조변수를 처음으로 할 경우
의원은 종합병원보다 OR 배 만큼 높거나 낮다,
병원은 종합병원보다 OR 배 만큼 높거나 낮다로 해석할 수 있다.
'머신러닝' 카테고리의 다른 글
| 머신러닝 Scikit-Learn 사용법 요약 (0) | 2021.08.06 |
|---|---|
| 머신러닝이란 (0) | 2021.08.06 |
| 의사결정 나무(Decision Tree) 쉽게 이해하기 (0) | 2021.08.06 |
| 머신러닝 개괄(오버피팅과 언더피팅, 모델링, 신호와 잡음) (0) | 2021.08.06 |
| 머신러닝 오버피팅의 개념과 해결 방법 (0) | 2021.08.06 |



댓글